The Project
So, if you’ve read my post on SEO, you know it can be hard to measure the impact your changes have on search result pages.
To get some rational foundation to evaluate your experiment on, you can use fancy, data-informed tools such as causal impact modeling. These models try to predict SEO performance based on historical data and check if your changes resulted in any significant deviation from said prediction.
The problem is that Google Search Console only keeps data for 16 months. You need more data to get better predictions.
The Design
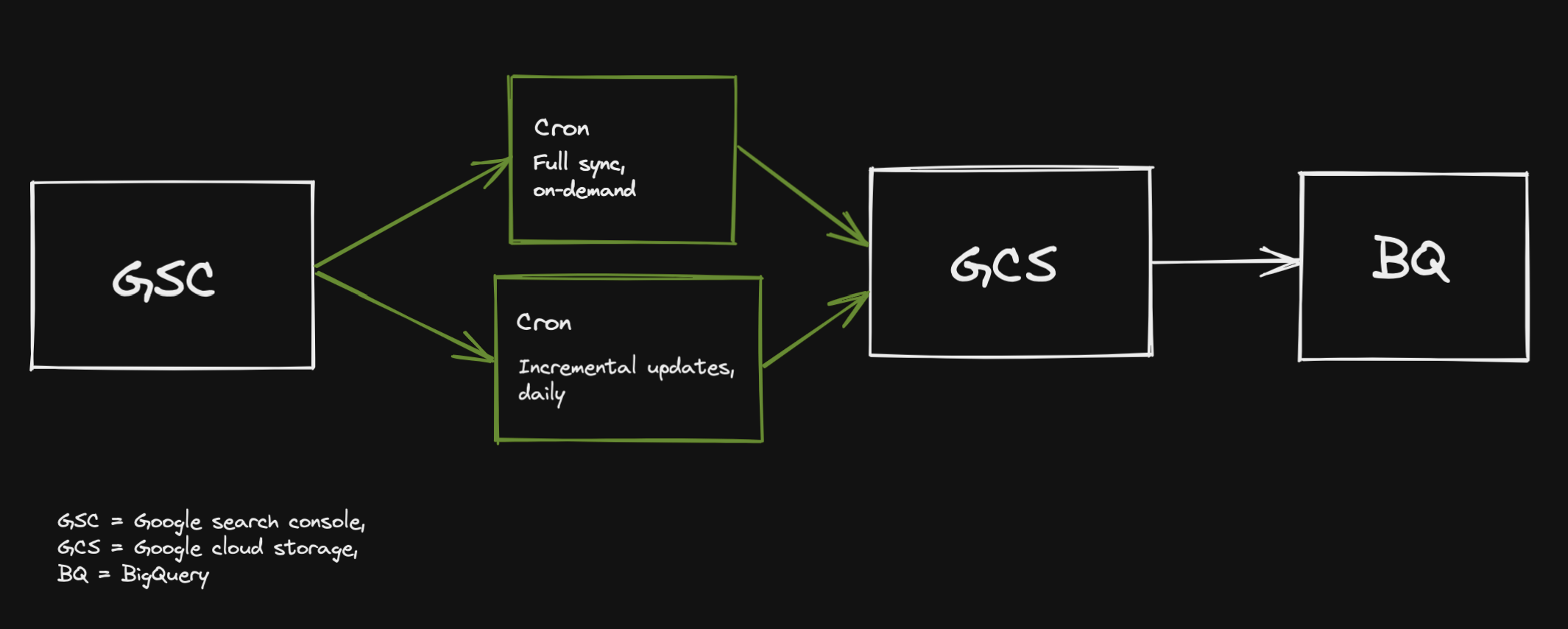
Simple enough, right? Create an application that loads data from GSC and stores it in GCS, then make it available in BQ as an external table.
Then have one “full-sync” cronjob that loads all data that is currently available and one that updates daily.
The Implementation
Here’s the story how my team and I went about implementing this design. We came out of the gate strong! Immediately, we found csharp clients for GSC and GCS and started coding. The data was easily serialized and stored in a GCS bucket.
We even noticed that each request only seems to return ~4k records, much less than the maximum of 25k. So we concluded that we did not need to implement any paging logic.
The whole thing was basically ready to be shipped in one day. To be honest, we didn’t even bother to unit test the code because it was so small. And to be even more honest, we didn’t write unit tests because we couldn’t mock the google API classes easily.
The Bugs
We got the code shipped quickly, but the bugs came in even faster. The dead canary in the mine was the feedback from our data analyst. He could not use the data we stored because critical data was missing. So we went back to add the missing features. Soon, we noticed that our assumption on paging was actually wrong, too.
Just because the API returns less records than their maximum, does not mean that a subsequent request won’t yield more results.
The GSC query API is pretty well documented and even tells you how to page through results. It returns HTTP status OK (200) for the the last page and will have an empty response (i.e., 0 rows).
Once we read about the status code, we continued reading. We learned about the various error response codes that can occur, some of which should be handled by our own application. We also learned about usage limits of the GSC API which our system needs to adhere to.
1 week later we were finally done and had a usable system. Time could have been saved and headaches could have been avoided if we just read through some documentation before writing the code. 🤕
The Learnings
💡 Show your stakeholders (in this case data analysts) a very early prototype of your solution.
💡 Don’t make assumptions on external APIs. RTFM.
💡 Ideally, create a design doc before you start writing code.
“Agile” does not give you an excuse to get things wrong when they could have been done right with a little bit of RTFM.
Thanks to my beautiful wife for proofreading this mess of an article ❤️
so long
comments powered by Disqus